Federated Learning (FL) facilitates collaborative training of a shared global model without exposing clients' private data. In practical FL systems, clients (e.g., edge servers, smartphones, and wearables) typically have disparate system resources. Conventional FL, however, adopts a one-size-fits-all solution, where a homogeneous large global model is transmitted to and trained on each client, resulting in an overwhelming workload for less capable clients and starvation for other clients. To address this issue, we propose FedConv, a client-friendly FL framework, which minimizes the computation and memory burden on resource-constrained clients by providing heterogeneous customized sub-models. FedConv features a novel learning-on-model paradigm that learns the parameters of the heterogeneous sub-models via convolutional compression. Unlike traditional compression methods, the compressed models in FedConv can be directly trained on clients without decompression. To aggregate the heterogeneous sub-models, we propose transposed convolutional dilation to convert them back to large models with a unified size while retaining personalized information from clients. The compression and dilation processes, transparent to clients, are optimized on the server leveraging a small public dataset. Extensive experiments on six datasets demonstrate that FedConv outperforms state-of-the-art FL systems in terms of model accuracy (by more than 35% on average), computation and communication overhead (with 33% and 25% reduction, respectively)
Federated Learning (FL) allows mobile devices to collaboratively train a shared global model without exposing their private data. In each communication round, clients keep their private data locally and only upload their model parameters or gradients to a server after local training. The server then orchestrates model aggregation and updates the global model for the next round.
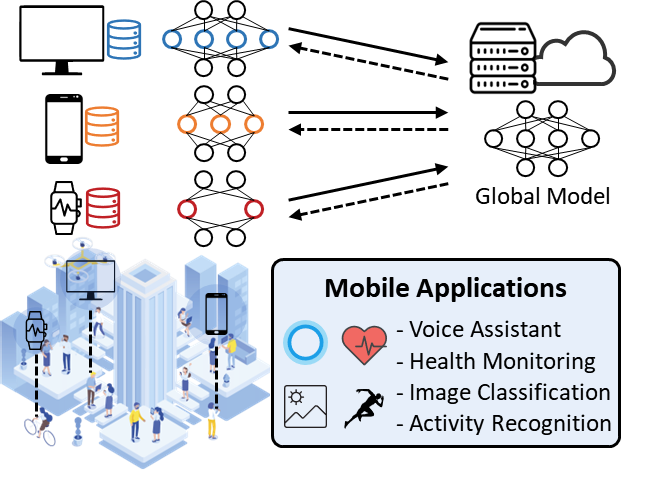
In real-world deployments, federated clients typically have diverse system resources, calling for heterogeneous models with different sizes. As shown in Fig. 1, high-end PCs can support large models, while wearables cannot. Simply assigning the smallest affordable model to all clients results in resource under-utilization and sub-optimal performance.
we propose FedConv, a client-friendly FL framework for heterogeneous models based on a new learning-on-model paradigm. The key insight is that convolution, a technique to extract effective features from data, can also compress large models via various receptive fields while preserving crucial information. In FedConv, the server performs convolutional compression on the global model to learn parameters of diverse sub-models according to clients' resource budgets. In model aggregation, the server first uses transposed convolution (TC) to transform heterogeneous client models into large models that have the same size as the global model. Then, the server assigns different learned weight vectors to these dilated models and aggregates them. FedConv optimizes the model compression, dilation, and aggregation processes by leveraging a small dataset on the server that can be obtained via crowdsourcing, or voluntarily shared by users without compromising their privacy. Therefore, our system does not incur extra communication or computation overhead for resource-constrained clients.
Fig. 2 shows the convolution-based compression process. To showcase that a compressed model generated by convolutional compression (compression layers) can effectively extract features from the input data, we compress a pre-trained ResNet18 model on the CIFAR10 dataset at a shrinkage ratio of 0.75. We then select the top-4 and top-3 feature maps with the highest importance outputted by a convolutional layer (measured by IG) from the large model and the sub-model, respectively. As shown in Fig. 2, both the large model and the sub-model can learn and focus on the key features (e.g., the deer's body, head, and horn). Moreover, compared with the large model, the first two feature maps from the sub-model pay more attention (deeper color) to the deer's body and ears. The third feature map can be regarded as a fusion of the last two feature maps from the large model, as it focuses on both the body and head of the deer. This observation indicates that the feature extraction capability of the large model can be effectively preserved and transferred to the sub-model via convolutional compression. Besides, the accuracy of the sub-model only decreases by 0.19% and the mutual information between the parameters of the large model and the sub-model is 3.09, which is much higher than that of the pruned model. This indicates that our proposed convolutional compression method can effectively minimize information loss after model compression.
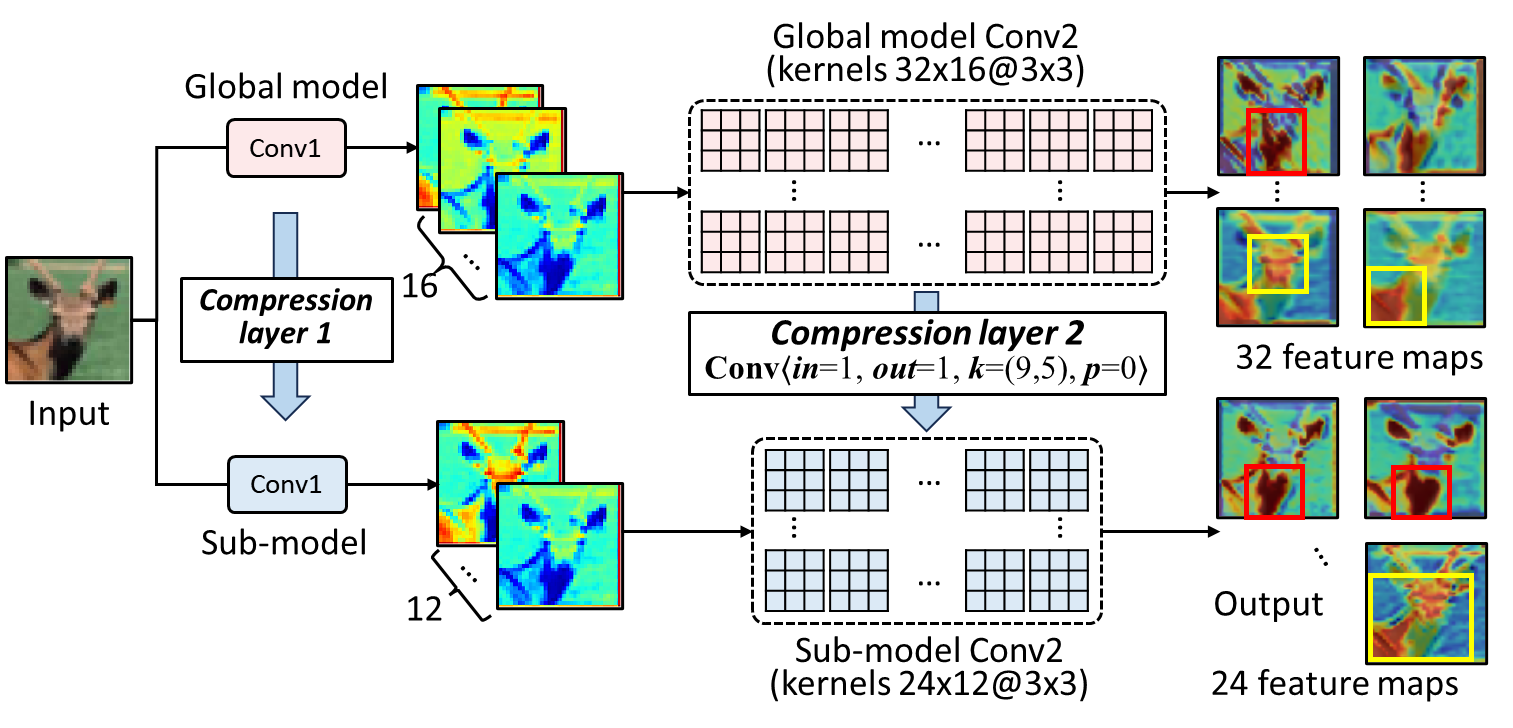
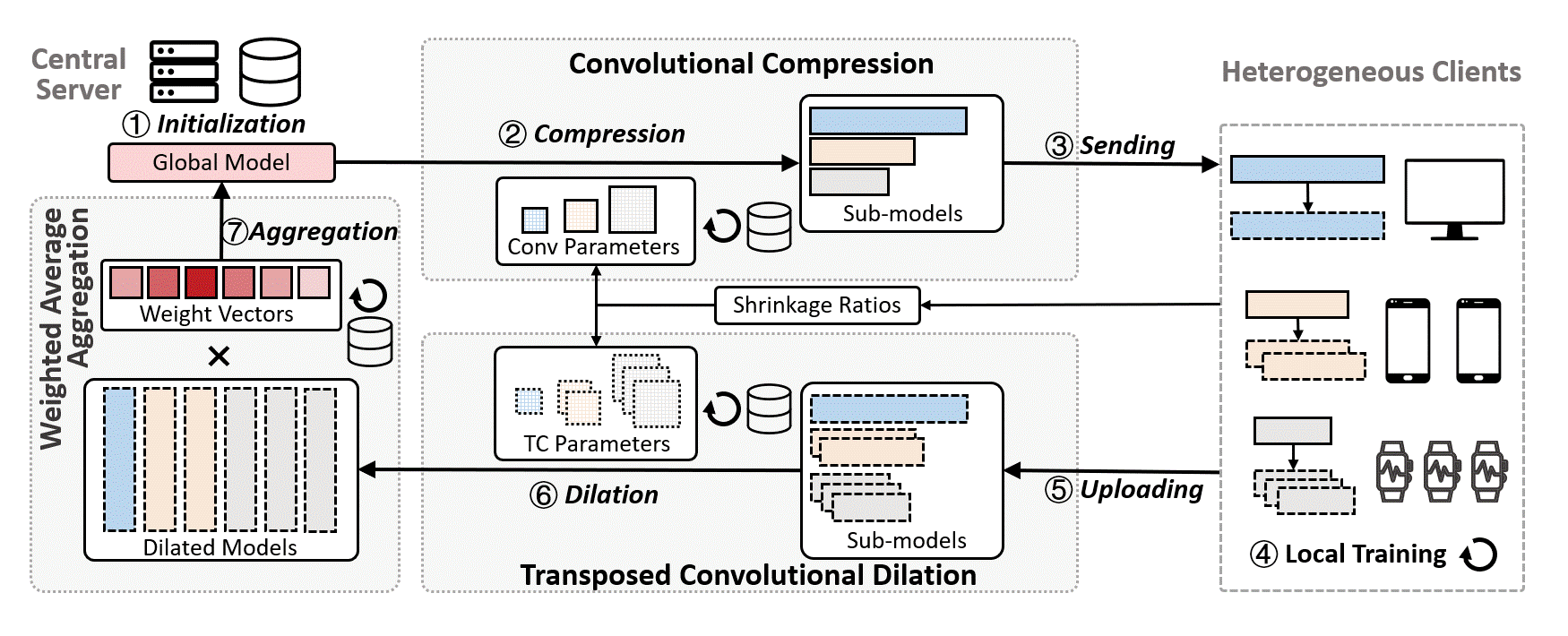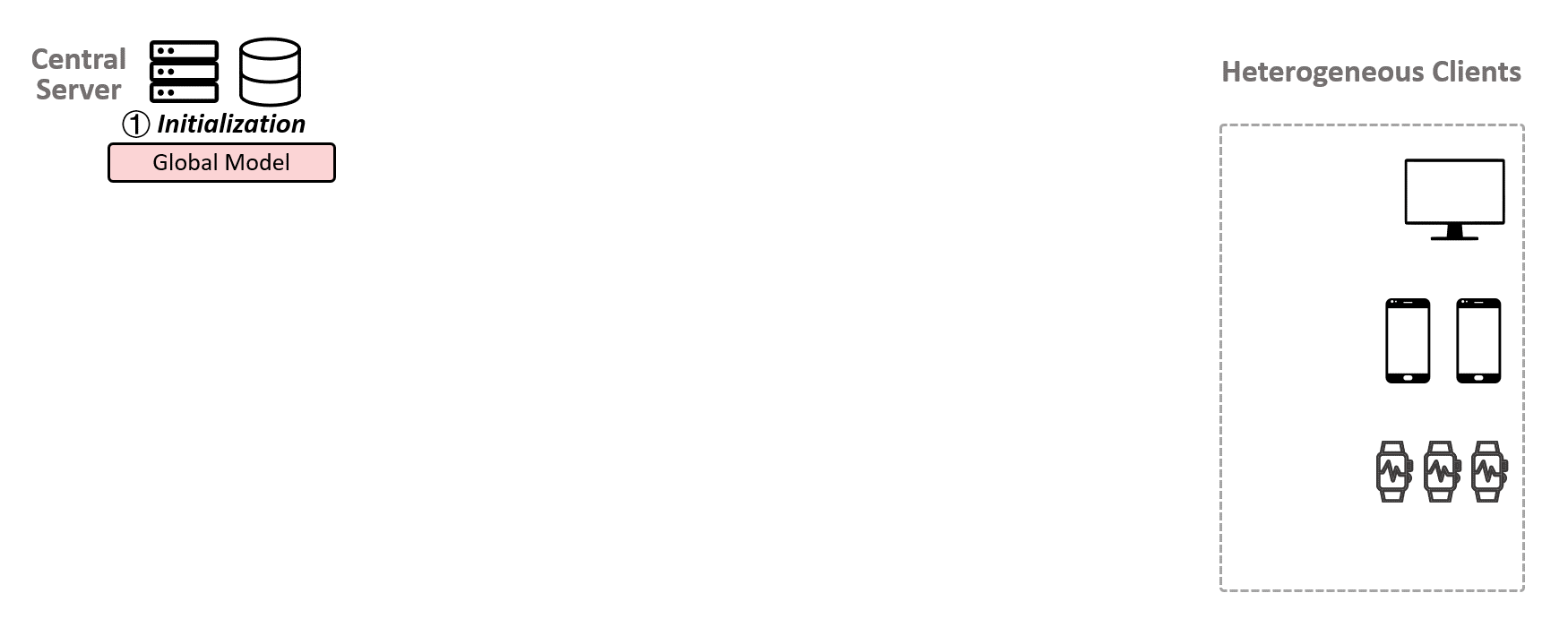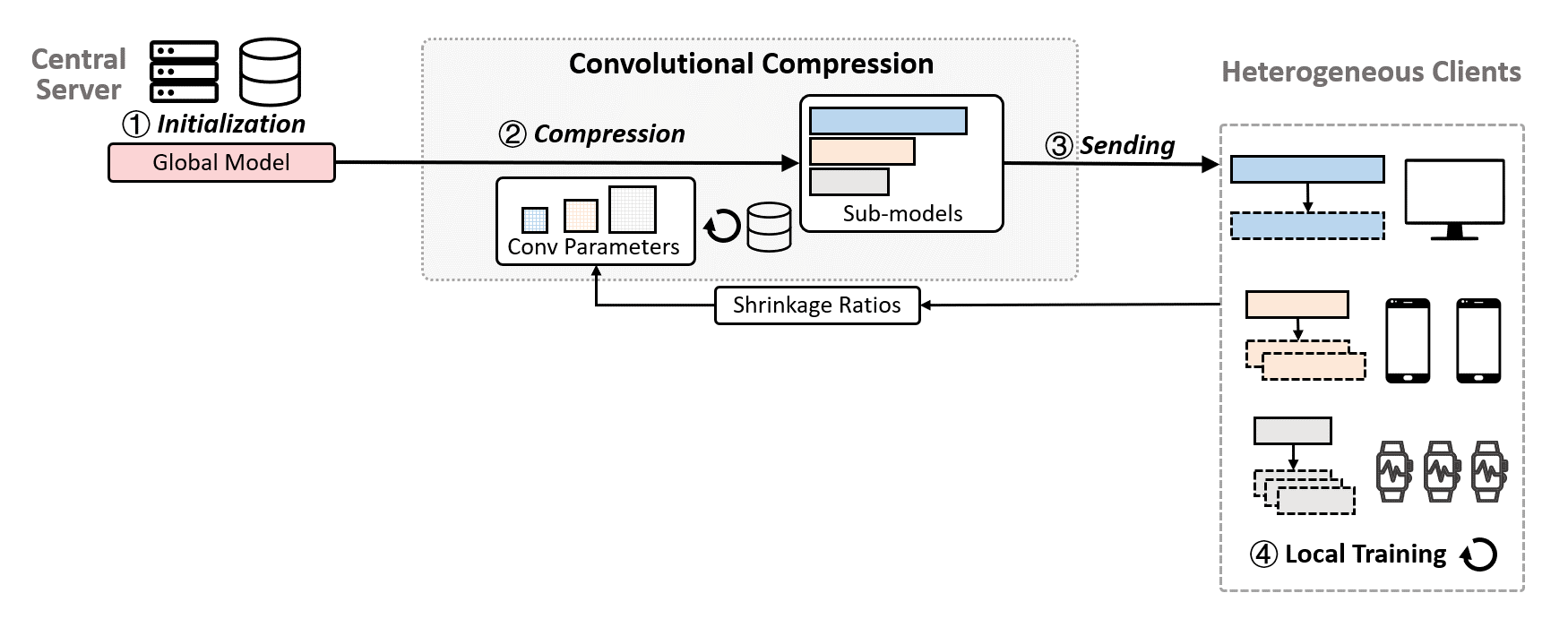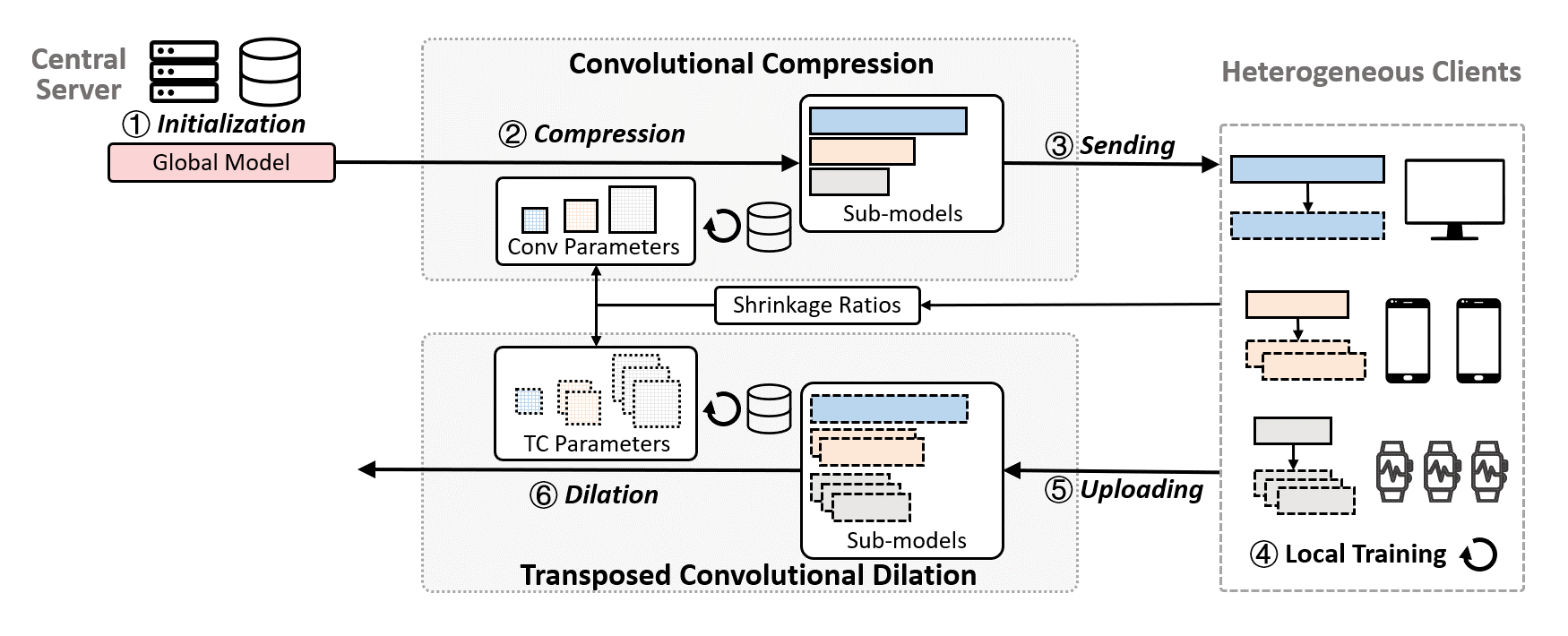
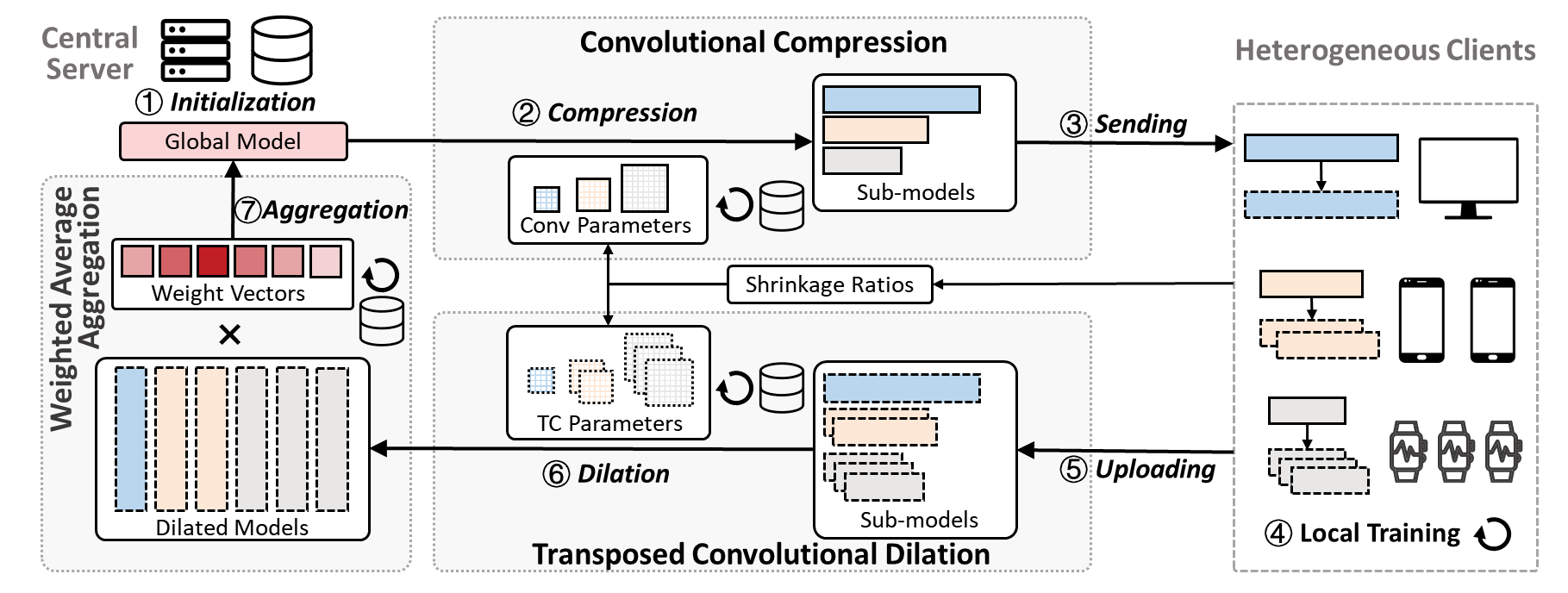
Fig. 3 illustrates the architecture of FedConv, consisting of three main modules: convolutional compression, transposed convolutional dilation, and weighted average aggregation.
The server first initializes a global model with an estimated memory requirement and records a set of shrinkage ratios (SR) reported by each client based on their resource profiles (①). In the first communication round, the server pre-trains the global model for several epochs with a server-side dataset to gain a better global view of the data distribution. Then, based on the SRs, a set of fine-tuned convolution parameters are used to compress the global model with the convolutional compression module, and generate heterogeneous sub-models (②). Afterwards, the server sends the heterogeneous sub-models to federated clients (③). Clients then perform several epochs of local training with their private training dataset to fine-tune the received sub-models (④), and then upload the updated parameters to the server (⑤). After that, the server performs the transposed convolutional dilation, where different transposed convolution parameters are used to dilate the sub-models to a set of large models that have the same size as the global model (⑥). Finally, the server applies the weighted average aggregation to aggregate the dilated models with the learned weights (⑦).
In FedConv, the compression and dilation operations are transparent to clients and performed by the powerful server, which can be seamlessly integrated into conventional FL systems where clients only need to perform local training.
We evaluate the overall performance of FedConv with heterogeneous models and data distribution.
We first evaluate the inference accuracy of the aggregated global model to demonstrate its generalizability. Standalone and FedMD are excluded because they do not create global models. Fig. 4(a) shows the global model accuracy under the same degree of heterogeneous data (𝛼=0.1). Serveralone achieves a higher global model accuracy than the baselines in most cases, as the server-side data for training and testing are both IID. FedConv achieves average improvements of 20.5%, 13.8%, and 10.5% when compared with pruning-based methods (Hermes and TailorFL), parameter sharing-based method (HeteroFL and FedRolex) and other baselines (FedAvg and LotteryFL), respectively. Since we assign the smallest affordable model to all clients in FedAvg, the client models have an insufficient number of parameters for training. Therefore, FedConv can outperform FedAvg even with IID data. This shows the superior generalization performance of the global in FedConv.
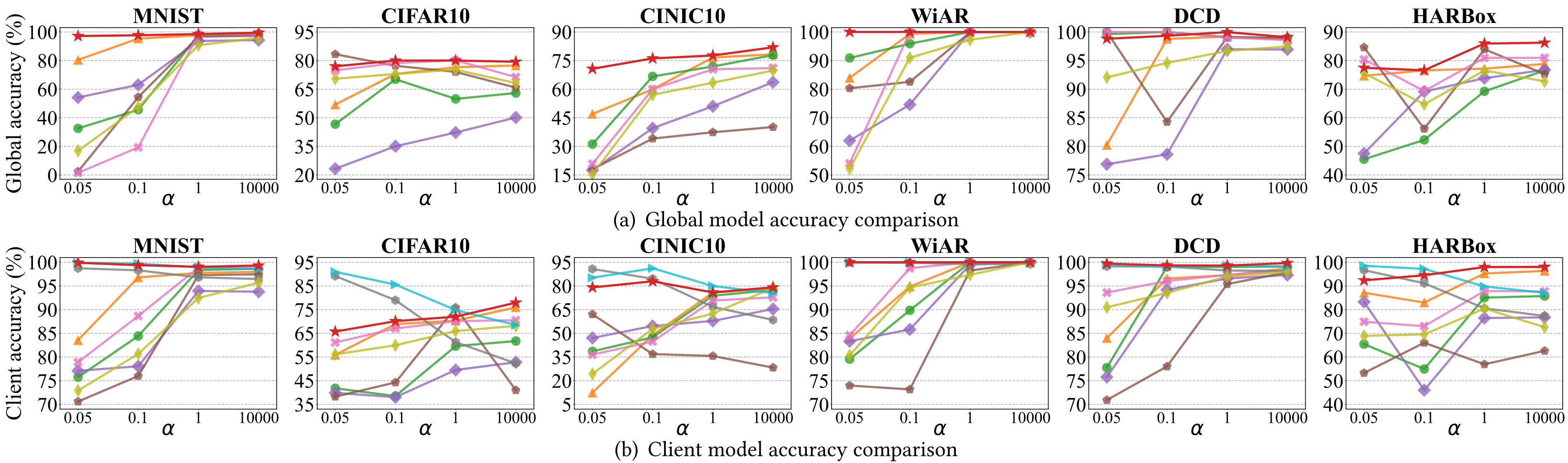
Moreover, Fig. 5(a) shows the global model accuracy of FedConv and all baselines across different data heterogeneity on all datasets. We can see that the performance enhancement of FedConv becomes more significant as 𝛼 decreases, meaning that FedConv can better cope with the increased data heterogeneity. Although FedConv does not obviously outperform FedAvg with homogeneous data, it exhibits better generalizability and robustness in the global model under heterogeneous data. FedConv also provides better personalization performance for clients. The performance improvements of the global model stem from our convolutional compression and TC dilation methods. They facilitate the information embedded in the global model being preserved and transferred from the server to clients through our learning-on-model approach.
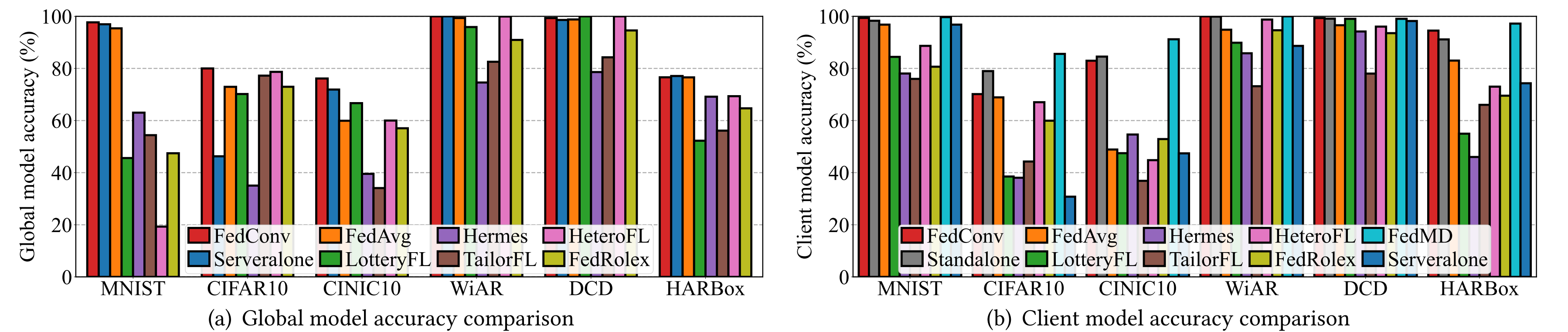
To evaluate the personalization performance of FedConv, we measure the inference accuracy of each client model with client-side test datasets and report the average value. Fig. 4(b) shows that with the same heterogeneous data settings, FedConv outperforms baselines (FedAvg, LotteryFL, Hermes, TailorFL, HeteroFL, and FedRolex) with accuracy improvements ranging from 8.4% to 50.6%. In Serveralone, when evaluating the global model using the client-side non-IID data, the accuracy of the client model drops below that of most baseline systems. This is because, in FedConv, the server-side data occupies a small portion of the entire dataset (5%). Therefore, Serveralone's global model hasn't seen sufficient data, leading to degraded performance on the client-side non-IID data.
Additionally, Fig. 5(b) shows the client model accuracy of FedConv and all baselines with different data heterogeneity on all datasets. It can be observed that the performance disparities become more substantial as 𝛼 decreases, implying that FedConv is more robust and can achieve consistently high accuracy across diverse data distribution. The performance gain of FedConv with heterogeneous data stems from the TC dilation process, where distinct TC parameters are assigned to each uploaded client model on the server. By employing varying TC parameters, the personalization information from clients will be preserved within the rescaled large models, which is then aggregated into the global model. Besides, we can see from Fig. 4(b) that, with sensing heterogeneity in the HARBox dataset, FedConv achieves a better and more stable performance. However, when 𝛼 is small (e.g., 𝛼 ∈ {0.05, 0.1} on CIFAR10), the client model accuracy of FedMD is higher than FedConv. The better performance stems from the distilled knowledge shared by all clients. Nonetheless, the downside is that it imposes excessive communication and computational overhead on clients. By contrast, FedConv can achieve comparable personalization performance without an extra burden on clients. In practice, we can further improve the personalization performance by adding task-specific layers.
We propose FedConv, a client-friendly federated learning framework for heterogeneous clients, aiming to minimize the system overhead on resource-constrained mobile devices. FedConv contributes three key technical modules: (1) a novel model compression scheme that generates heterogeneous sub-models with convolutional compression on the global model; (2) a transposed convolutional dilation module that converts heterogeneous client models back to large models with a unified size; and (3) a weighted average aggregation scheme that fully leverages personalization information of client models to update the global model. Extensive experiments demonstrate that FedConv outperforms SOTA baselines in terms of inference accuracy with much lower computation and communication overhead for FL clients. We believe the proposed learning-on-model paradigm is worthy of further exploration and can potentially benefit other FL tasks where heterogeneous sub-models can be generated to retain the information of a global model.
For more details, please refer to our Paper.
The code for implementing FedConv is available at here.
@inproceedings{shen2024fedconv,
title={FedConv: A Learning-on-Model Paradigm for Heterogeneous Federated Clients},
author={Shen, Leming and Yang, Qiang and Cui, Kaiyan and Zheng, Yuanqing and Wei, Xiao-yong and Liu, Jianwei and Han, Jinsong},
booktitle={Proceedings of the 22st Annual International Conference on Mobile Systems, Applications and Services},
pages={1--14},
year={2024}
}